Category Archives: Industry
Why developers make superior operators
Developers who deeply understand the arcana of infrastructure, and operators who can code and understand the interaction of applications and infrastructure, are better than developers and operators who understand only their own discipline. But it’s typically easier, from the perspective of training, for a developer to learn operations, than for an operator to learn development.
While there are fair number of people who teach themselves on-the-job, most developers still come out of formal computer science backgrounds. The effectiveness of formal education in CS varies immensely, and you can get a good understanding by reading on your own, of course, if you read the right things — it’s the knowledge that matters, not how you got it. But ideally, a developer should accumulate the background necessary to understand the theory of operating systems, and then have a deeper knowledge of the particular operating system that they primarily work with, as well as the arcana of the middleware. It’s intensely useful to know how the abstract code you write, actually turns out to run in practice. Even if you’re writing in a very high-level programming language, knowing what’s going on under the hood will help you write better code.
Many people who come to operations from the technician end of things never pick up this kind of knowledge; a lot of people who enter either systems administration or network operations do so without the benefit of a rigorous education in computer science, whether from college or self-administered. They can do very well in operations, but it’s generally not until you reach the senior-level architects that you commonly find people who deeply understand the interaction of applications, systems, and networks.
Unfortunately, historically, we have seen this division in terms of relative salaries and career paths for developers vs. operators. Operators are often treated like technicians; they’re often smart learn-on-the-job people without college degrees, but consequently, companies pay accordingly and may limit advancement paths accordingly, especially if the company has fairly strict requirements that managers have degrees. Good developers often emerge from college with minimum competitive salary requirements well above what entry-level operations people make.
Silicon Valley has a good collection of people with both development and operations skills because so many start-ups are founded by developers, who chug along, learning operations as they go, because initially they can’t afford to hire dedicated operations people; moreover, for more than a decade, hypergrowth Internet start-ups have deliberately run devops organizations, making the skillset both pervasive and well-paid. This is decidedly not the case in most corporate IT, where development and operations tend to have a hard wall between them, and people tend to be hired for heavyweight app development skills, more so than capabilities in systems programming and agile-friendly languages.
Here are my reasons for why developers make better operators, or perhaps more accurately, an argument for why a blended skillset is best. (And here I stress that this is personal opinion, and not a Gartner research position; for official research, check out the work of my esteemed colleagues Cameron Haight and Sean Kenefick. However, as someone who was formally educated as a developer but chose to go into operations, and who has personally run large devops organizations, this is a strongly-held set of opinions for me. I think that to be a truly great architect-level ops person, you also have to have a developer’s skillset, and I believe it’s important to mid-level people as well, which I recognize as a controversial opinions.)
Understanding the interaction of applications and infrastructure leads to better design of both. This is an architect’s role, and good devops understand how to look at applications and advise developers how they can make them more operations-friendly, and know how to match applications and infrastructure to one another. Availability, performance, and security are all vital to understand. (Even in the cloud, sharp folks have to ask questions about what the underlying infrastructure is. It’s not truly abstract; your performance will be impacted if you have a serious mismatch between the underlying infrastructure implementation and your application code.)
Understanding app/infrastructure interactions leads to more effective troubleshooting. An operator who can CTrace, DTrace, sniff networks, read application code, and know how that application code translates to stuff happening on infrastructure, is in a much better position to understand what’s going wrong and how to fix it.
Being able to easily write code means less wasted time doing things manually. If you can code nearly as quickly as you can do something by hand, you will simply write it as a script and never have to think about doing it by hand again — and neither will anyone else, if you have a good method for script-sharing. It also means that forever more, this thing will be done in a consistent way. It is the only way to truly operate at scale.
Scripting everything, even one-time tasks, leads to more reliable operations. When working in complex production environments (and arguably, in any environment), it is useful to write out every single thing you are going to do, and your action plan for any stage you deem dangerous. It might not be a formal “script”, but a command-by-command plan can be reviewed by other people, and it means that you are not making spot decisions under the time pressure of a maintenance window. Even non-developers can do this, of course, but most don’t.
Converging testing and monitoring leads to better operations. This is a place where development and operations truly cross. Deep monitoring converges into full test coverage, and given the push towards test-driven development in agile methodologies, it makes sense to make production monitoring part of the whole testing lifecycle.
Development disciplines also apply to operations. The systems development lifecycle is applicable to operations projects, and brings discipline to what can otherwise be unstructured work; agile methodologies can be adapted to operations. Writing the tests first, keeping things in a revision control system, and considering systems holistically rather than as a collection of accumulated button-presses are all valuable.
The move to cloud computing is a move towards software-defined everything. Software-defined infrastructure and programmatic access to everything inherently advantages developers, and it turns the hardware-wrangling skills into things for low-level technicians and vendor field engineering organizations. Operations becomes software-oriented operations, one way or another, and development skills are necessary to make this transition.
It is unfortunately easier to teach operations to developers, than it is to teach operators to code. This is especially true when you want people to write good and maintainable code — not the kind of script in which people call out to shell commands for the utilities that they need rather than using the appropriate system libraries, or splattering out the kind of program structure that makes re-use nigh-impossible, or writing goop that nobody else can read. This is not just about the crude programming skills necessary to bang out scripts; this is about truly understanding the deep voodoo of the interactions between applications, systems, and networks, and being able to neatly encapsulate those things in code when need be.
Devops is a great place for impatient developers who want to see their code turn into results right now; code for operations often comes in a shorter form, producing tangible results in a faster timeframe than the longer lifecycles of app development (even in agile environments). As an industry, we don’t do enough to help people learn the zen of it, and to provide career paths for it. It’s an operations specialty unto itself.
Devops is not just a world in which developers carry pagers; in fact, it doesn’t necessarily mean that application developers carry pagers at all. It’s not even just about a closer collaboration between development and operations. Instead, it can mean that other than your most junior button-pushers and your most intense hardware specialists, your operations people understand both applications and infrastructure, and that they write code as necessary to highly automate the production environment. (This is more the philosophy of Google’s Site Reliability Engineering, than it is Amazon-style devops, in other words.)
But for traditional corporate IT, it means hiring a different sort of person, and paying differently, and altering the career path.
A little while back, I had lunch with a client from a mid-market business, which they spent telling me about how efficient their IT had become, especially after virtualization — trying to persuade me that they didn’t need the cloud, now or ever. Curious, I asked how long it typically took to get a virtualized server up and running. The answer turned out to be three days — because while they could push a button and get a VM, all storage and networking still had to be manually provisioned. That led me to probe about a lot of other operations aspects, all of which were done by hand. The client eventually protested, “If I were to do the things you’re talking about, I’d have to hire programmers into operations!” I agreed that this was precisely what was needed, and the client protested that they couldn’t do that, because programmers are expensive, and besides, what would they do with their existing do-everything-by-hand staff? (I’ve heard similar sentiments many times over from clients, but this one really sticks in my mind because of how shocked this particular client was by the notion.)
Yes. Developers are expensive, and for many organizations, it may seem alien to use them in an operations capacity. But there’s a cost to a lack of agility and to unnecessarily performing tasks manually.
But lessons learned in the hot seat of hypergrowth Silicon Valley start-ups take forever to trickle into traditional corporate IT. (Even in Silicon Valley, there’s often a gulf between the way product operations works, and the way traditional IT within that same company works.)
To become like a cloud provider, fire everyone here
A recent client inquiry of mine involved a very large enterprise, who informed me that their executives had decided that IT should become more like a cloud provider — like Google or Facebook or Amazon. They wanted to understand how they should transform their organization and their IT infrastructure in order to do this.
There were countless IT people on this phone consultation, and I’d received a dizzying introducing to names and titles and job functions, but not one person in the room was someone who did real work, i.e., someone who wrote code or managed systems or gathered requirements from the business, or even did higher-level architecture. These weren’t even people who had direct management responsibility for people who did real work. They were part of the diffuse cloud of people who are in charge of the general principle of getting something done eventually, that you find everywhere in most large organizations (IT or not).
I said, “If you’re going to operate like a cloud provider, you will need to be willing to fire almost everyone in this room.”
That got their attention. By the time I’d spent half an hour explaining to them what a cloud provider’s organization looks like, they had decidedly lost their enthusiasm for the concept, as well as been poleaxed by the fundamental transformations they would have to make in their approach to IT.
Another large enterprise client recently asked me to explain Rackspace’s organization to them. They wanted to transform their internal IT to resemble a hosting company’s, and Rackspace, with its high degree of customer satisfaction and reputation for being a good place to work, seemed like an ideal model to them. So I spent some time explaining the way that hosting companies organize, and how Rackspace in particular does — in a very flat, matrix-managed way, with horizontally-integrated teams that service a customer group in a holistic manner, coupled with some shared-services groups.
A few days later, the client asked me for a follow-up call. They said, “We’ve been thinking about what you’ve said, and have drawn out the org… and we’re wondering, where’s all the management?”
I said, “There isn’t any more management. That’s all there is.” (The very flat organization means responsibility pushed down to team leads who also serve functional roles, a modest number of managers, and a very small number of directors who have very big organizations.)
The client said, “Well, without a lot of management, where’s the career path in our organization? We can’t do something like this!”
Large enteprise IT organizations are almost always full of inertia. Many mid-market IT organizations are as well. In fact, the ones that make me twitch the most are the mid-market IT directors who are actually doing a great job with managing their infrastructure — but constrained by their scale, they are usually just good for their size and not awesome on the general scale of things, but are doing well enough to resist change that would shake things up.
Business, though, is increasingly on a wartime footing — and the business is pressuring IT, usually in the form of the development organization, to get more things done and to get them done faster. And this is where the dissonance really gets highlighted.
A while back, one of my clients told me about an interesting approach they were trying. They had a legacy data center that was a general mess of stuff. And they had a brand-new, shiny data center with a stringent set of rules for applications and infrastructure. You could only deploy into the new shiny data center if you followed the rules, which gave people an incentive to toe the line, and generally ensured that anything new would be cleanly deployed and maintained in a standardized manner.
It makes me wonder about the viability of an experiment for large enterprise IT with serious inertia problems: Start a fresh new environment with a new philosophy, perhaps a devops philosophy, with all the joy of having a greenfield deployment, and simply begin deploying new applications into it. Leave legacy IT with the mess, rather than letting the morass kill every new initiative that’s tried.
Although this is hampered by one serious problem: IT superstars rarely go to work in enterprises (excepting certain places, like some corners of financial services), and they especially don’t go to work in organizations with inertia problems.
IT Operations and button-pushing
The fine folks at Nodeable gave me an informal introductory briefing today; they’ve got a pretty cool concept for a cloud-oriented monitoring and management SaaS-based tool that’s aimed at DevOps.
I’ve been having stray thoughts on DevOps and the future of IT Operations in the couple of hours that have passed since then, and reflecting on the following problem:
At an awful lot of companies, IT Operations, especially lower-level folks, are button-pushing monkeys — specifically, they are people who know how to use the vendor-supplied GUI to perform particular tasks. They may know the vendor-recommended ways to do things with a particular bit of hardware or software. But only a few of them have architect-level knowledge, the deep understanding of the esoterica of systems and how this stuff is actually built and engineered. (Some of this is a reflection of education; a lot of IT Operations people don’t come from a computer science background, but have what they’ve needed to know on the job.)
Today’s DevOps person is likely to have a skillset that we used to call systems programming. They understand systems architecture, they understand operating systems, they can write system-level code, including the scripting necessary for automation. The programmatic access to infrastructure exemplified by cloud IaaS providers has moved this up a layer of abstraction, so that you don’t have to be a deep-voodoo guy to do this kind of thing.
We’re moving towards a world where you have really low-level button-pushers — possibly where the button-pushing is so simple that you don’t need a specialist to do it any longer, anyone reasonably technical can do it — and senior architects whoo design things, and systems programmers who automate things. Whether those systems programmers work in application development and are “DevOps”, or whether those systems programmers work in IT Operations and just happen to be systems guys who program (mostly scripting), doesn’t really matter — the era of the button-pusher is drawing towards its close either way, at least for organizations who are going to efficiently increase IT Operations efficiency.
I want to share a story. It is, in some ways, a story about cruelty and unprofessionalism, but it’s funny in its own way.
About fifteen years ago, I was working as an engineer at Digex (the first real managed hosting company). We had a pretty highly skilled group of engineers there, and we never did anything using a GUI. We had hundreds of customers on dedicated Sun servers, and you’d either SSH into the systems or, in a pinch, go to the data center and log in on console. We were also the kind of people who would fix issues by making kernel modifications — for instance, the day that the SYN flood attack showed up, a bunch of customers went down hard, meaning that we could not afford to wait for Sun to come up with a patch, since we had customer SLAs to meet, so one of our security engineers rewrote the kernel’s queueing code for TCP accepts.
We were without a manager for some time, and they finally hired a guy who was supposedly a great Sun sysadmin. He didn’t actually get a technical interview, but he had a good work history of completed projects and happy teams and so forth. He was supposed to be both the manager and the technical lead for the team.
The problem was that he had no idea how to do anything that wasn’t in Sun’s administrator GUI. He didn’t even know how to attach a console cable to a server, much less log in remotely to a system. Since we did absolutely nothing with a GUI, this was a big problem. An even bigger problem was that he didn’t understand anything about the underlying technologies we were supporting. If he had a problem, he was used to calling Sun and having them tell him what to do. This, clearly, is a big problem in a managed hosting environment where you’re the first line of support for your customers, who may do arbitrary wacky things.
He also worked a nine-to-five day at a startup where engineers routinely spent sixteen hours at work. His team, and the other engineers at the company, had nothing but contempt for him. And one night, having dinner at 10 pm as a break before going right back into work, someone had an idea.
“Let’s recompile his kernel without mouse support.” (Like all the engineers, he had a Sun workstation at his desk.)
And so when he came to work the next morning, his mouse didn’t work — and every trace of the intrusion had been covered, thanks to the complicity of one of the security engineers.
Someone who had an idea of what he was doing wouldn’t have been phazed; they’d have verified the mouse wasn’t working, then done an L1-A to put the workstation into PROM mode, and easily done troubleshooting from there (although admittedly, nobody thinks, “I wonder if somebody recompiled my kernel without mouse support after I went home last night”). This poor guy couldn’t do anything other than pick up his mouse to make sure the underside hadn’t gotten dirty. It turned out that he had no idea how to do anything with the workstation if he couldn’t log in via the GUI.
It proved to be a remarkably effective demonstration to management that this guy was a yahoo and needed to be fired. (Fortunately, there were plenty of suspect engineers, and management never found out who was responsible. Earl Galleher, who ran that part of the business at the time, and is the chairman at Basho now, probably still wonders… It wasn’t me, Earl.)
But it makes me wonder what is the future of all the GUI masters in IT Operations, because the world is evolving to be more like the teams that I had before I came to Gartner — systems programmers with strong systems and operations skills, who could also code.
DevOps: Now you know how to deal with the IT Operations guy who can only use a GUI…
What does the future of the data center look like to you?
Earlier this year, I was part of a team at Gartner that took a futuristic view of the data center, in a scenario-planning exercise. The results of that work have been published as The Future of the Data Center Market: Four Scenarios for Strategic Planning (Gartner clients only). My blog entries today are by my colleague, project leader Joe Skorupa, and provide a glimpse into this research. See the introduction for more information.
The Scenarios
Scenarios are defined by the 4 quadrants that result from the intersection of the axes of uncertainty. In defining our scenarios we deliberately did not choose technology-related axes because they were too limiting and because larger macro forces were potentially more disruptive.
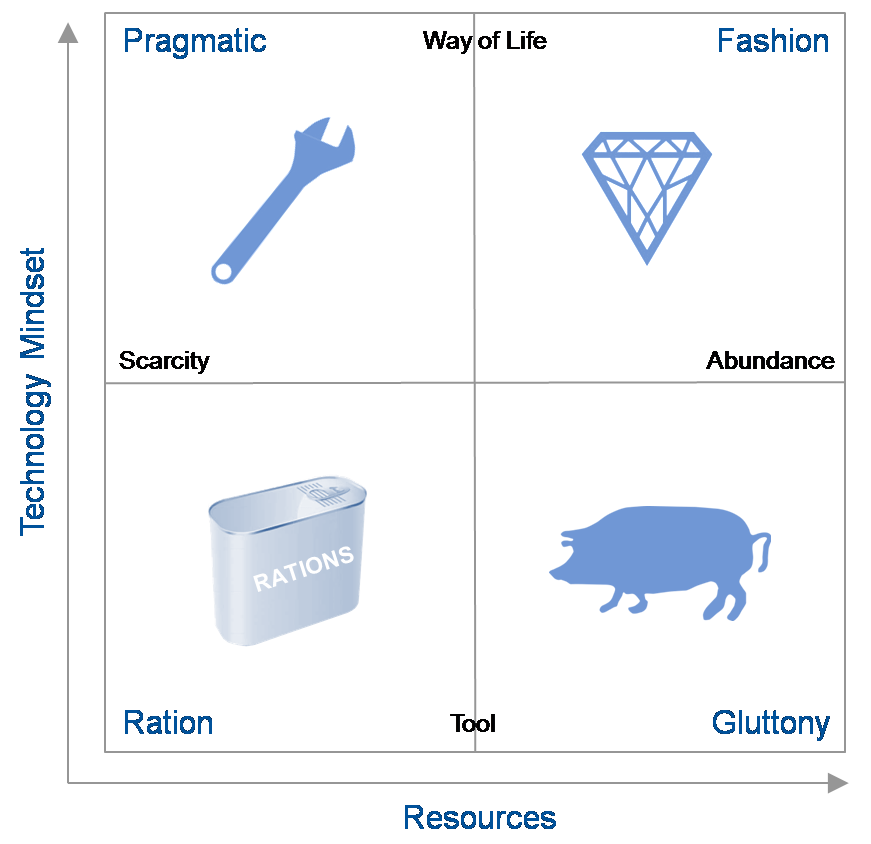
We focused on exploring how the different external factors outlined by the two axes would affect the environment into which companies would provide the products and services. Note that these external macro forces do contain technological elements.
The vertical axis describes the role and relevance of technology in the minds of the consumers and providers of technology while the horizontal axis describes availability of resources – human capital (workers with the right skill set), financial capital (investments in hardware, software, facilities or internal development) or natural resources, particularly energy — to provide IT. The resulting quadrants describe widely divergent possible futures.
- The “Tech Ration” Scenario
- This scenario describes the world in 2021 that is characterized by severely limited economic, energy, skill and technological resources needed to get the job done. People view technology as they used to think of the telephone – as a tool for a given purpose. After a decade of economic decline, wars, increasingly scarce resources and protectionist government reactions, most businesses are survival-focused.
Key Question: What would be the impact of a closed-down, localized view of the world on your strategic plans?
- The “Tech Pragmatic” Scenario
- This scenario presents a similar world of limited resources but where people are highly engaged with IT and it forms a key role in their lifestyles. Social networks and communities evolved over the decade into sources of innovation, application development and services. IT plays a major role in coordinating and orchestrating the ever-changing landscape of technology and services.
Key Question: Will your strategy be able to cope with a world of limited resources but the need for agility to meet user demands?
- The “Tech Fashion” Scenario
- This scenario continues the theme where the digital natives’ perspectives have evolved to where technology is an integral part of people’s lives. The decade preceding 2021 saw a social-media-led peace, a return to economic growth, and a flourishing of technology from citizen innovators. It is a world of largely unconstrained resources and limited government. Businesses rely on technology to maximize their opportunities. However, consumers demand the latest technology and expect it to be effective.
Key Question: How will a future where the typical IT consumer owns multiple devices and expects to access any application from every one of their devices affect your strategic planning?
- The “Tech Gluttony” Scenario
- This scenario continues in 2021 with unconstrained resources where people view technology as providing separate tools for a given purpose. Organizations developed situation-specific products and applications. Users and consumers view their technology tools as limited life one-offs. IT budgets become focused on integrating a constantly shifting landscape of tools.
Key Question: Does a world of excessive numbers of technological tools from myriad suppliers change your strategic planning?
The four scenario stories each depicts the journey to and a description of a plausible 2021 world. Of course the real future is likely to be a blend of two or more of the scenarions. To gain maximum value, you should treat each story as a history and description of the world as it is. To gain maximum benefit suspend disbelief, immerse yourself in the story, and take time to reflect on the implications for your business and enter into discussion on what plans would be most beneficial as the future unfolds.
ObPlug: Of course, Gartner analysts are available to assist in deriving specific implications for your business and formulating appropriate plans.
Introduction to the Future of the Data Center Market
Earlier this year, I was part of a team at Gartner that took a futuristic view of the data center, in a scenario-planning exercise. The results of that work have been published as The Future of the Data Center Market: Four Scenarios for Strategic Planning (Gartner clients only). My blog entries today are by my colleague, project leader Joe Skorupa, and provide a glimpse into this research.
Introduction
As a data center focused provider, how do you formulate strategic plans when the pace and breadth of change makes the future increasingly uncertain? Historical trends and incremental extrapolations may provide guidance for the next few years, but these approaches rarely account for disruptive change. Many Gartner clients that sell into the data center requested help formulating long-range strategic plans that embrace uncertainty. To assist our clients, a team of 15 Gartner from across a wide range of IT disciplines employed the scenario-based planning process to develop research about the future of the data center market. Unlike typical Gartner research, we did not focus on 12-18 month actionable advice; we focused on potential market developments/disruptions in the 2016-2021 timeframe. As a result its primary audience is C-level executives that their staffs that are responsible for long-term strategic planning. Product line managers and competitive analysts may also find this work useful.
Scenario-based planning was adopted by the US Department of Defense in the 1960s and the formal scenario-based planning framework was developed at Royal Dutch Shell in the 1970s. It has been applied to many organizations, from government entities to private companies, around the world to identify major disruptors that could impact an organization’s ability to maintain or gain competitive advantage. For this effort we used the process to identify and assess major changes in social, technological, economic, environmental and political (STEEP) environments.
These scenarios are told as stories and are not meant to be predictive and the actual future will be some subset of one or more of the stories. However, they provide a basis for deriving company-specific implications and developing a strategy to enable your company to move forward and adapt to uncertainty as the future unfolds. Exploring alternative future scenarios that are created by such major changes should lead to the discovery of potential opportunities in the market or to ensure the viability of current business models that may be critical to meeting future challenges.
To anchor the research, we focused on the following question (the Focal Issue) and its corollary:
Focal Issue: With rapidly changing end-user IT/services needs and requirements, what will be the role of the data center in 2021 and how will this affect my company’s competitiveness?
Corollary: How will the role of the data center affect the companies that sell products or services into this market?
The next post describes the scenarios themselves.
Recent research notes
This is just a quick call-out to draw your attention to the research that I’ve published recently.
- Do You Have a Business Case for a Top-Level Domain?
- I blogged previously on this topic, and this research note, done with my colleague Ray Valdes (whose coverage includes online user experience), dives deeply into consideration of the uses of gTLDs, the impact of gTLDs, the shifting landscape of how users find websites, and other things of interest to anyone considering a gTLD or preparing a business case for one.
- How to Deliver Video to Dispersed Users Without Upgrading Your Network
- Many organizations that are trying to deliver video to a lot of users think that they should use a traditional CDN. That’s not necessarily the right solution. This research note examines the range of solutions, divided by the delivery targets — Internet users outside your organization, your own employees at remote sites, Internet VPN users, and mixed-usage scenarios.
- How to Accelerate Internet Websites and Applications
- There are a range of techniques that can be used for acceleration — netwok optimization, front-end optimization (sometimes called Web content optimization or Web performance optimization), and caching — that can be delivered as appliances or services. This research note looks at selecting the right solution, and combining solutions, to maximize performance within your available budget.
(These notes are for Gartner clients only, sorry.)
OpenStack, community, and commercialization
I wrote, the other day, about Citrix buying Cloud.com, and I realized I forgot to make an important point about OpenStack versus the various commercial vendors vying for the cloud-building market; it’s worthy of a post on its own.
OpenStack is designed by the community, which is to say that it’s largely designed by committee, with some leadership that represents, at least in theory, the interests of the community and has some kind of coherent plan in mind. It is implemented by the community, which means that people who want to contribute simply do so. If you want something in OpenStack, you can write it and hope that your patches are included, but there’s no guarantee. If the community decides something should be included in OpenStack, they need some committers to agree to actually write it, and hope that they implement it well and do it in some kind of reasonable timeframe.
This is not the way that one normally deals with software vendors, of course. If you’re a potentially large customer and you’d like to use Product X but it doesn’t contain Feature Y that’s really important to you, you can normally say to the vendor, “I will buy X if you had Y within Z timeframe,” and you can even write that into your contract (usually witholding payment and/or preventing the vendor from recognizing the revenue until they do it).
But if you’re a potentially large customer that would happily adopt OpenStack if it just had Feature Y, you have miminal recourse. You probably don’t actually want to write Feature Y yourself, and even if you did, you would have no guarantee that you wouldn’t be maintaining a fork of the code; ditto if you paid some commercial entity (like one of the various ventures that do OpenStack consulting). You could try getting Feature Y through the community process, but that doesn’t really operate on the timeframe of business, nor have any guarantees that it’ll be successful, and also requires you to engage with the community in a way that you may have no interest in doing. And even if you do get it into the general design, you have no control over implementation timeframe. So that’s not really doable for a business that would like to work with a schedule.
There are a growing number of OpenStack startups that aim to offer commercial distributions with proprietary features on top of the community OpenStack core, including Nebula and Piston (by Chris Kemp and Joshua McKenty, respectively, and funded by Kleiner Perkins and Hummer Winblad, respectively, two VCs who usually don’t make dumb bets). Commercial entities, of course, can deal with this “I need to respond to customer needs more promptly than the open source community can manage” requirement.
There are many, many entitities, globally, telling us that they want to offer a commercial OpenStack distribution. Most of these are not significant forks per se (although some plan to fork entirely), but rather plans to pick a particular version of the open source codebase and work from there, in order to try to achieve code stability as well as add whatever proprietary features are their secret source. Over time, that can easily accrete into a fork, especially because the proprietary stuff can very easily clash with whatever becomes part of OpenStack’s own core, given how early OpenStack is in its evolution.
Importantly, OpenStack flavors are probably not going to be like Linux distributions. Linux distributions differ mostly in which package manager they use, what packages are installed by default, and the desktop environment config out of the box — almost cosmetic differences, although there can be non-cosmetic ones (such as when things like virtualization technologies were supported). Successful OpenStack commercial ventures need to provide significant value-add and complete solutions, which, especially in the near term when OpenStack is still a fledgling immature project, will result in a fragmentation of what features can be expected out of a cloud running OpenStack, and possibly significant differences in the implementation of critical underlying functionality.
I predict most service providers will pick commercial software, whether in the form of VMware, Cloud.com, or some commercial distribution of OpenStack. Ditto most businesses making use of cloud stack software to do something significant. But the commercial landscape of OpenStack may turn out to be confusing and crowded.
Citrix buys Cloud.com
(This is part of a series of “catch-up” posts of announcements that I’ve wanted to comment on but didn’t previously find time to blog about.)
Recently, Citrix acquired Cloud.com. The purchase price was reported to be in the $200m+ vicinity — around 100x revenues. (Even in this current run of outsized valuations, that’s a rather impressive payday for an infrastructure software start-up. I heard that VMware’s Paul Maritz was talking about how these guys were shopping themselves around, into which some people have read that they ‘had’ to sell, but companies that sell themselves for 100x trailing revenues don’t ‘have’ to be doing anything, other than sniffing around to see if anyone is willing to give them even more money.)
Cloud.com (formerly known as VMOps) is one of a great many “cloud operating system” companies — it competes with Abiquo, OpenStack, Eucalyptus, Nimbula, VMware (in the form of vCloud Director), and so on. By that, I mean that you can take Cloud.com and use it to build cloud IaaS of your very own. While you can use Cloud.com to build a private cloud, the reason that Cloud.com commanded such a high valuation is that it’s currently the primary alternative to VMware for service providers who want to build public cloud IaaS.
Cloud.com is a commercial open-source vendor, but realistically, it’s heavily on the commercial side, not the open-source side; people running Cloud.com in production are generally using the licensed, much more featureful, version. Large service providers who want to build commodity clouds, particularly on the Xen hypervisor (especially Citrix Xen, rather than open-source Xen), are highly likely to choose Cloud.com’s CloudStack product as the underlying “cloud OS”. We’re also increasingly hearing from service providers who intend to use Cloud.com to manage VMware-based environments (using the VMware stack minus vCloud Director), as part of a hypervisor-neutral strategy.
Key service provider customers include GoDaddy and Tata Communications. A particular private cloud customer of note is Zynga, which uses Cloud.com to provide Amazon-compatible (and thus Rightscale-compatible) infrastructure internally, letting it easily move workloads across their own infrastructure and Amazon’s.
Citrix, of course, now has a significant commitment to OpenStack, in the form of Project Olympus, their planned commercial distribution. The Cloud.com acquisition is nevertheless complementary, though, not competitive to the OpenStack commitment.
Cloud.com provides a much more complete set of features than OpenStack — it’s got much of what you need to have a turnkey cloud. Over time, as OpenStack matures, Cloud.com will be able to replace the lower levels of its software stack with OpenStack components instead. For Citrix, though (and broadly, service providers interested in VMware alternatives), this is a time-to-market issue as well as a solution-completeness issue.
In my conversations with a variety of organizations that are deeply strategically involved with OpenStack and working in-depth on the codebase, consensus seems to have developed that OpenStack is about 18 months from maturity (in the sense that it will be stable enough for a service provider who needs to depend on it to run their business to be able to reasonably do so). That’s forever in this fast-moving market. While Swift (the storage piece) is currently reliable and in production use at a variety of service providers, Nova (the compute piece) is not — there are no major service providers running Nova, and it’s acknowledged to not be service-provider-ready. (Rackspace is running the code it got via the acquisition of Slicehost, not the Nova project.) Service providers want to work with proven, stable code, and that’s not Nova right now — that’s Cloud.com. (Or VMware, and even there, people have been touchy about vCloud Director.)
It’s not that the service providers have a deep interest in running an open-source codebase; rather, they are looking for an alternative to VMware that is less expensive. Cloud.com currently fills that need reasonably well.
Similarly, it’s not that most of the members of the OpenStack coalition are vastly interested in an open-source cloud world, but rather, that they realize that there needs to be an alternative to VMware’s ecosystem, and it is in the best interests of VMware’s various competitors to pool their efforts (and for vendors in more of an “arms merchant” role, to ensure that their stuff works with every ecosystem out there). Open source is a means to an end there. Cloud.com’s stack, whether commercial or open source, is only a benefit to the OpenStack project, in the long term.
This acquisition means something pretty straightforward: Citrix is ensuring that it can deliver a full service provider stack of software that will enable providers to successfully compete against vCloud — or to have hypervisor-neutral solutions peacefully coexist, in a way that can be easily blended to meet business needs for a broad range of IaaS solutions. While Citrix would undoubtedly love to sell more XenServer licenses, ultimately the real money is in selling the rest of its portfolio to service providers — like NetScaler ADCs. Having a hypervisor-neutral cloud stack benefits Citrix’s overall position, even if some Cloud.com customers will choose to go VMware or KVM or open-source Xen rather than Citrix Xen for the hypervisor.
It certainly doesn’t hurt that Cloud.com’s Amazon-compatible APIs (and thus support of RightScale’s functionality) is also tremendously useful for organizations seeking to build Amazon-compatible private clouds at scale. No one else has really addressed this need, and VMware (in an infrastructure context) has largely targeted the market for “dependable”, classically enterprise-like infrastructure, rather than explored the opportunities in the emerging demand for commodity cloud.
In short, I think Cloud.com is a great buy for Citrix, and VMware-watchers interested in whether or not their vCloud service provider initiative is working well should certainly track Cloud.com wins vs. vCloud wins in the service provider space.
Akamai and Riverbed partner on SaaS delivery
Akamai and Riverbed have signed a significant partnership deal to jointly develop solutions that combine Internet acceleration with WAN optimization. The two companies will be incorporating each other’s technologies into their platforms; this is a deep partnership with significant joint engineering, and it is probably the most significant partnership that Akamai has done to date.
Akamai has been facing increasing challenges to its leadership in the application acceleration market — what Akamai’s financial statements term “value added services”, including their Dynamic Site Accelerator (DSA) and Web Application Accelerator (WAA) services, which are B2C and B2B bundles, respectively, built on top of the same acceleration delivery network (ADN) technology. Vendors such as Cotendo (especially via its AT&T partnership), CDNetworks, and EdgeCast now have services that compete directly with what has been, for Akamai, a very high-margin, very sticky service. This market is facing severe pricing pressure, due not just to competition, but due to the delta between the cost of these services and standard CDN caching. (In other words, as basic CDN services get cheaper, application acceleration also needs to get cheaper, in order to demonstrate sufficient ROI, i.e., business value of performance, above just buying the less expensive solution.)
While Akamai has had interesting incremental innovations and value-adds since it obtained this technology via the 2007 acquisition of Netli, it has, until recently, enjoyed a monopoly on these services, and therefore hasn’t needed to do any groundbreaking innovation. While the internal enterprise WAN optimization market has been heavily competitive (between Riverbed, Cisco, and many others), other CDNs largely only began offering competitive ADN solutions in the last year. Now, while Akamai still leads in performance, it badly needs to open up some differentiation and new potential target customers, or it risks watching ADN solutions commoditize just the way basic CDN services have.
The most significant value proposition of the joint Akamai/Riverbed solution is this:
Despite the fundamental soundness of the value proposition of ADN services, most SaaS providers use only a basic CDN service, or no CDN at all. The same is true of other providers of cloud-based services. Customers, however, frequently want accelerated services, especially if they have end-users in far-flung corners of the globe; the most common problem is poor performance for end-users in Asia-Pacific when the service is based in the United States. Yet, today, doing so either requires that the SaaS provider buy an ADN service themselves (which it’s hard to do for only one customer, especially for multi-tenant SaaS), or requires the SaaS provider to allow the customer to deploy hardware in their data center (for instance, a Riverbed Steelhead WOC).
With the solution that this partnership is intended to produce, customers won’t need a SaaS provider’s cooperation to deploy an acceleration solution — they can buy it as a service and have the acceleration integrated with their existing Riverbed solution. It adds significant value to Riverbed’s customers, and it expands Akamai’s market opportunity. It’s a great idea, and in fact, this is a partnership that probably should have happened years ago. Better late than never, though.
What CenturyLink is Getting with Savvis
I scribbled off a quick blog post on the CenturyLink acquisition of Savvis but didn’t have time to delve into it in detail at the time. This is a bit of a follow-up.
Savvis has three core businesses:
- Coloation: Savvis has carrier-diverse (though not strictly-speaking carrier neutral), high-quality colocation in data centers around the world. It is one of the most significant players in retail colocation for enterprises. It also has a substantial financial vertical play in its proximity hosting for low-latency trading.
- Managed Hosting: Savvis is among the market share leaders in managed hosting. It is a highly capable provider, ranked for years as a Leader (and at or near the top of the pack) in Gartner’s Magic Quadrant for the market.
- Networking: Although Savvis has a history as an ISP, their significant acquisition of networking assets came with the acquisition of Cable and Wireless North America’s assets (which included a substantial amount of MCI assets that had to be divested in the MCI-WorldCom acquisition), which they did in order to get Exodus. The networking business has been in slow decline for years, although it has some usefulness in competing with BT Radiance, in the proximity hosting context.
As part of their managed hosting business, Savvis has built a significant portfolio of cloud IaaS products. Savvis has historically had a tendency to overcomplicate their product lines, and cloud has been no exception to this rule. The most significant elements in the portfolio are Virtual Intelligent Hosting (utility managed hosting, equivalent to Terremark Infinistructure, AT&T Synaptic Hosting, etc.), and Symphony VPDC (self-service public cloud, equivalent to Terremark Enterprise Cloud, AT&T Synaptic CaaS, Verizon CaaS, NaviSite NaviCloud, etc.), which is divided into tiers of service quality. Savvis also has an array of private cloud services.
We consider Savvis to be highly competitive in enterprise-class cloud IaaS. They do not necessarily have the best service, featurewise, and they are a relatively expensive option, but they have done a credible job of incorporating security into their architecture, emphasized in RFP responses, in a way that customers respond to very strongly. Savvis has also done a good job layering managed services on top of their cloud offerings, and has begun to compete quite aggressively in the cloud-enabled data center outsourcing market segment, targeting mid-market companies.
In short, CenturyLink is buying a very high-quality set of assets. Qwest has a colocation business, but it is marred by poor customer service (it’s pretty hard to deliver poor customer service in a business as simple as colocation, but Qwest has historically managed to do this, although quality varies per-data-center). Qwest also has a managed hosting business, but it’s historically been sub-par to the market and well behind the hosting businesses of AT&T and Verizon. Qwest’s forays into cloud computing are embryonic. Consequently, CenturyLink is vastly accelerating its entry into this business with the Savvis acquisition. Also, given the capabilities gap between CenturyLink and Savvis, customers can probably expect little if any disruption from the acquisition.
It’s clear that carriers, even the less visionary ones, now feel that they need to have solutions to address data center needs, not just networking needs. While some carriers were able to articulate a vision around this relatively early on — AT&T notably — all the other network operators are quickly falling in line, albeit with varying degrees of vision and commitment.
